
Development of early HTTP Requests for Comments (RFCs) started a few years later and it was a coordinated effort by the Internet Engineering Task Force (IETF) and the World Wide Web Consortium (W3C), with work later moving to the IETF.
URL beginning with the HTTP scheme and the WWW domain name label
HTTP functions as a request–response protocol in the client–server model. A web browser, for example, may be the client whereas a process, named web server, running on a computer hosting one or more websites may be the server. The client submits an HTTP request message to the server. The server, which provides resources such as HTML files and other content or performs other functions on behalf of the client, returns a response message to the client. The response contains completion status information about the request and may also contain requested content in its message body.
HTTP is designed to permit intermediate network elements to improve or enable communications between clients and servers. High-traffic websites often benefit from web cache servers that deliver content on behalf of upstream servers to improve response time. Web browsers cache previously accessed web resources and reuse them, whenever possible, to reduce network traffic. HTTP proxy servers at private network boundaries can facilitate communication for clients without a globally routable address, by relaying messages with external servers.
To allow intermediate HTTP nodes (proxy servers, web caches, etc.) to accomplish their functions, some of the HTTP headers (found in HTTP requests/responses) are managed hop-by-hop whereas other HTTP headers are managed end-to-end (managed only by the source client and by the target web server).
HTTP resources are identified and located on the network by Uniform Resource Locators (URLs), using the Uniform Resource Identifiers (URI’s) schemes http and https. As defined in RFC 3986, URIs are encoded as hyperlinks in HTML documents, so as to form interlinked hypertext documents.
HTTP/2 is a revision of previous HTTP/1.1 in order to maintain the same client–server model and the same protocol methods but with these differences in order:
- to use a compressed binary representation of metadata (HTTP headers) instead of a textual one, so that headers require much less space;
- to use a single TCP/IP (usually encrypted) connection per accessed server domain instead of 2 to 8 TCP/IP connections;
HTTP/2 communications therefore experience much less latency and, in most cases, even more speed than HTTP/1.1 communications.
W3C HTTP Working Group
W3C HTTP-NG Working Group
IETF HTTP Working Group restarted
SPDY: an unofficial HTTP protocol developed by Google
2014 updates to HTTP/1.1
In June 2014, the HTTP Working Group released an updated six-part HTTP/1.1 specification obsoleting RFC2616:
- RFC 7230, HTTP/1.1: Message Syntax and Routing
- RFC 7231, HTTP/1.1: Semantics and Content
- RFC 7232, HTTP/1.1: Conditional Requests
- RFC 7233, HTTP/1.1: Range Requests
- RFC 7234, HTTP/1.1: Caching
- RFC 7235, HTTP/1.1: Authentication
- it has no HTTP headers and lacks many other features that nowadays are required for minimal security reasons;
- it has not been widespread since 1999..2000 (because of HTTP/1.0 and HTTP/1.1) and is commonly used only by some very old network hardware, i.e. routers, etc.
- RFC 9110, HTTP Semantics
- RFC 9111, HTTP Caching
- RFC 9112, HTTP/1.1
- RFC 9113, HTTP/2
- RFC 9114, HTTP/3 (see also the section above)
- RFC 9204, QPACK: Field Compression for HTTP/3
- RFC 9218, Extensible Prioritization Scheme for HTTP
In HTTP/0.9, the TCP/IP connection is always closed after server response has been sent, so it is never persistent.
HTTP/1.1 added also HTTP pipelining in order to further reduce lag time when using persistent connections by allowing clients to send multiple requests before waiting for each response. This optimization was never considered really safe because a few web servers and many proxy servers, specially transparent proxy servers placed in Internet / Intranets between clients and servers, did not handle pipelined requests properly (they served only the first request discarding the others, they closed the connection because they saw more data after the first request or some proxies even returned responses out of order etc.). Besides this only HEAD and some GET requests (i.e. limited to real file requests and so with URLs without query string used as a command, etc.) could be pipelined in a safe and idempotent mode. After many years of struggling with the problems introduced by enabling pipelining, this feature was first disabled and then removed from most browsers also because of the announced adoption of HTTP/2.
HTTP/2 extended the usage of persistent connections by multiplexing many concurrent requests/responses through a single TCP/IP connection.
HTTP/3 does not use TCP/IP connections but QUIC + UDP (see also: technical overview).
- Content retrieval optimizations
- Response status codes
- HTTP Request Structure
- Using HTTP methods in Restful API development
- What is a Safe HTTP method?
- GET Method
- How to test an API with a GET method?
- POST Method
- How to test a POST endpoint
- PUT Method
- How to test an API with a PUT method?
- PATCH Method
- How to test an API with a PATCH method?
- DELETE Method
- How to test a DELETE endpoint?
- HEAD Method
- OPTIONS Method
- How to test an OPTIONS endpoint
- TRACE Method
- How to test an API with a TRACE method?
- CONNECT Method
- Browser Support
- FAQ
- What is the difference between PUT and PATCH?
- Does the GET method accept the request body?
- What does idempotency mean?
- What is CORS?
Content retrieval optimizations
a requested resource was always sent entirely.
HTTP/1.0 added headers to manage resources cached by client in order to allow conditional GET requests; in practice a server has to return the entire content of the requested resource only if its last modified time is not known by client or if it changed since last full response to GET request. One of these headers, «Content-Encoding», was added to specify whether the returned content of a resource was or was not compressed.If the total length of the content of a resource was not known in advance (i.e. because it was dynamically generated, etc.) then the header «Content-Length: number» was not present in HTTP headers and the client assumed that when server closed the connection, the content had been entirely sent. This mechanism could not distinguish between a resource transfer successfully completed and an interrupted one (because of a server / network error or something else).
- new headers to better manage the conditional retrieval of cached resources.
- chunked transfer encoding to allow content to be streamed in chunks in order to reliably send it even when the server does not know in advance its length (i.e. because it is dynamically generated, etc.).
Both HTTP/2 and HTTP/3 have kept the above mentioned features of HTTP/1.1.
HTTP provides multiple authentication schemes such as basic access authentication and digest access authentication which operate via a challenge–response mechanism whereby the server identifies and issues a challenge before serving the requested content.
The authentication mechanisms described above belong to the HTTP protocol and are managed by client and server HTTP software (if configured to require authentication before allowing client access to one or more web resources), and not by the web applications using a web application session.
Host: www.example.com
Accept-Language: en
- an empty line, consisting of a carriage return and a line feed;
- an optional message body.
In the HTTP/1.1 protocol, all header fields except Host: hostname are optional.
An HTTP/1.1 request made using telnet. The request message, response header section, and response body are highlighted.
A request method is safe if a request with that method has no intended effect on the server. The methods GET, HEAD, OPTIONS, and TRACE are defined as safe. In other words, safe methods are intended to be read-only. They do not exclude side effects though, such as appending request information to a log file or charging an advertising account, since they are not requested by the client, by definition.
In contrast, the methods POST, PUT, DELETE, CONNECT, and PATCH are not safe. They may modify the state of the server or have other effects such as sending an email. Such methods are therefore not usually used by conforming web robots or web crawlers; some that do not conform tend to make requests without regard to context or consequences.
A request method is cacheable if responses to requests with that method may be stored for future reuse. The methods GET, HEAD, and POST are defined as cacheable.
In contrast, the methods PUT, DELETE, CONNECT, OPTIONS, TRACE, and PATCH are not cacheable.
Request header fields allow the client to pass additional information beyond the request line, acting as request modifiers (similarly to the parameters of a procedure). They give information about the client, about the target resource, or about the expected handling of the request.
HTTP/1.1 200 OK
Response status codes
In HTTP/1.0 and since, the first line of the HTTP response is called the status line and includes a numeric status code (such as «404») and a textual reason phrase (such as «Not Found»). The response status code is a three-digit integer code representing the result of the server’s attempt to understand and satisfy the client’s corresponding request. The way the client handles the response depends primarily on the status code, and secondarily on the other response header fields. Clients may not understand all registered status codes but they must understand their class (given by the first digit of the status code) and treat an unrecognized status code as being equivalent to the x00 status code of that class.
The first digit of the status code defines its class:
4XX (client error)
5XX (server error)
The server failed to fulfill an apparently valid request.
The response header fields allow the server to pass additional information beyond the status line, acting as response modifiers. They give information about the server or about further access to the target resource or related resources.
Each response header field has a defined meaning which can be further refined by the semantics of the request method or response status code.
gzip, deflate, br
Mon, 23 May 2005 22:38:34 GMT
Wed, 08 Jan 2003 23:11:55 GMT
Apache/1.3.3.7 (Unix) (Red-Hat/Linux)
An Example Page
Hello World, this is a very simple HTML document.
Most of the header lines are optional but some are mandatory. When header «Content-Length: number» is missing in a response with an entity body then this should be considered an error in HTTP/1.0 but it may not be an error in HTTP/1.1 if header «Transfer-Encoding: chunked» is present. Chunked transfer encoding uses a chunk size of 0 to mark the end of the content. Some old implementations of HTTP/1.0 omitted the header «Content-Length» when the length of the body entity was not known at the beginning of the response and so the transfer of data to client continued until server closed the socket.
A «Content-Encoding: gzip» can be used to inform the client that the body entity part of the transmitted data is compressed by gzip algorithm.
- The Gopher protocol is a content delivery protocol that was displaced by HTTP in the early 1990s.
- The Gemini protocol is a Gopher-inspired protocol which mandates privacy-related features.
- InterPlanetary File System — can replace http
- Comparison of file transfer protocols
- Content negotiation
- Digest access authentication
- HTTP compression
- List of HTTP header fields
- List of HTTP status codes
- Representational state transfer (REST)
- Variant object
- Web cache
- WebSocket
- In practice, these streams are used as multiple TCP/IP sub-connections to multiplex concurrent requests/responses, thus greatly reducing the number of real TCP/IP connections on server side, from 2..8 per client to 1, and allowing many more clients to be served at once.
- In 2022, HTTP/0.9 support has not been officially completely deprecated and is still present in many web servers and browsers (for server responses only), even if usually disabled. It is unclear how long it will take to decommission HTTP/0.9.
- HTTP/2 and HTTP/3 have a different representation for HTTP methods and headers.
- HTTP/1.0 has the same messages except for a few missing headers.
- HTTP/2 and HTTP/3 use the same request / response mechanism but with different representations for HTTP headers.
- «Change History for HTTP». W3.org. Retrieved . A detailed technical history of HTTP.
- «Design Issues for HTTP». W3.org. Retrieved . Design Issues by Berners-Lee when he was designing the protocol.
HTTP protocol works by clients sending requests to the servers and servers responding to the requests. We do CRUD operations (Create, Read, Update, Delete) by sending HTTP requests with different HTTP methods, sometimes called HTTP verbs. GET and POST are the most frequently used HTTP methods, but more HTTP methods are to learn. This article will go through different HTTP methods and how to use them when building and using web APIs.
Table of Contents
- HTTP Request Structure
- Using HTTP methods in Restful API development
- Comparison of HTTP methods
- Browser Support
- FAQ
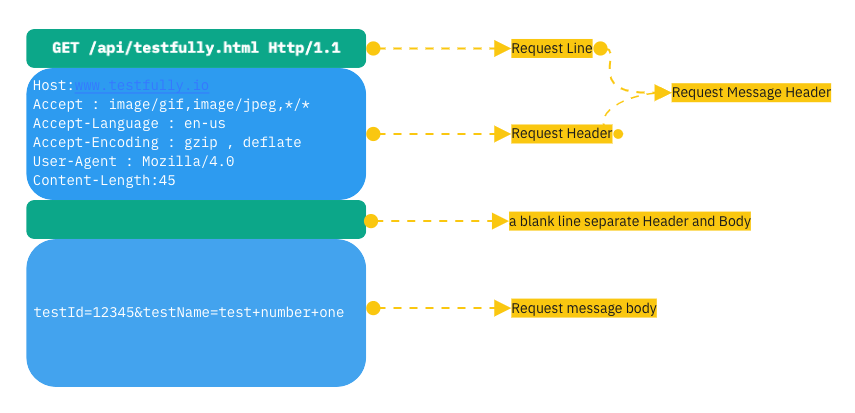
HTTP Request Structure
- A request-line
- An empty line (a line with nothing before CRLF shows the end of the fields)
- A message-body (optional)
Using HTTP methods in Restful API development
REST is the abbreviation of Representational State Transfer, and it is an architectural pattern for creating web services. Web services that use the REST principles are the RESTful web services. These web services are used by application developers widely because they simply communicate with other servers on different machines.
What is a Safe HTTP method?
By now, you have a good understanding of how HTTP protocol works, different HTTP methods, and why we should use them. This section will cover each method in more depth, so without further ado, let’s get started with GET, the most popular HTTP method out there.
GET Method
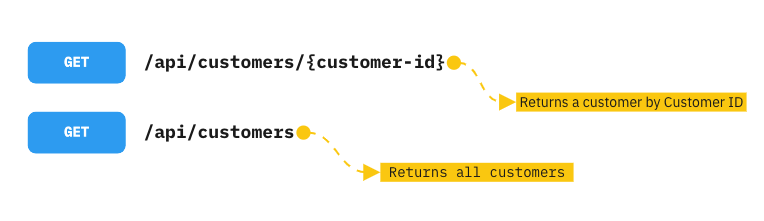
If we want to retrieve data from a resource like websites, servers or APIs, we send them a GET Request. For example, we send a GET request to the server if we want a list of our customers or a specific customer.
Since the GET method should never change the data on the resources and just read them(read-only), it is considered a Safe Method. Additionally, the Get method is idempotent.
How to test an API with a GET method?
- If the resource is accessible, the API returns the 200 Status Code, which means OK.
- If the server does not support the endpoint, the server returns the 404 Status Code, which means Not Found.
- If we send the request in the wrong syntax, the server returns the 400 Status Code, which means Bad Request.
POST Method
The POST method creates a new resource on the backend (server). The request body carries the data we want to the server.
It is neither a safe nor idempotent method. We don’t expect to get the same result every time we send a POST request. For example, two identical POST requests will create two new equivalent resources with the same data and different resource ids.
- Ideally, if the POST request has created a new resource on the other side, the response should come with 201 Status Code which means Created.
- Sometimes, performing a POST request doesn’t return a resource at the given URL; in this case, the method will return 204 status code which means No content.

How to test a POST endpoint
Since the POST method creates data, we must be cautious about changing data; testing all the POST methods in APIs is highly recommended. Moreover, make sure to delete the created resource once your testing is finished.
Here are some suggestions that we can do for testing APIs with POST methods:
- Create a resource with the POST method, and it should return the 201 Status Code.
- Perform the GET method to check if it created the resource was successfully created. You should get the 200 status code, and the response should contain the created resource.
- Perform the POST method with incorrect or wrong formatted data to check if the operation fails.
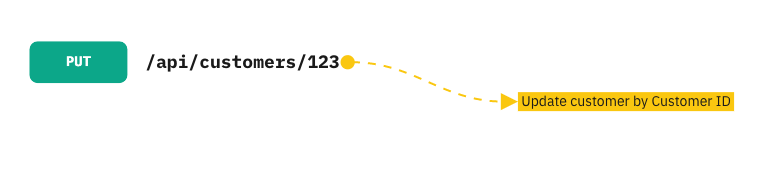
PUT Method
With the PUT request method, we can update an existing resource by sending the updated data as the content of the request body to the server. The PUT method updates a resource by replacing its entire content completely. If it applies to a collection of resources, it replaces the whole collection, so be careful using it. The server will return the 200 or 204 status codes after the existing resource is updated successfully.
How to test an API with a PUT method?
- Send a PUT request to the server many times, and it should always return the same result.
- When the server completes the PUT request and updates the resource, the response should come with 200 or 204 status codes.
- After the server completes the PUT request, make a GET request to check if the data is updated correctly on the resource.
- If the input is invalid or has the wrong format, the resource must not be updated.
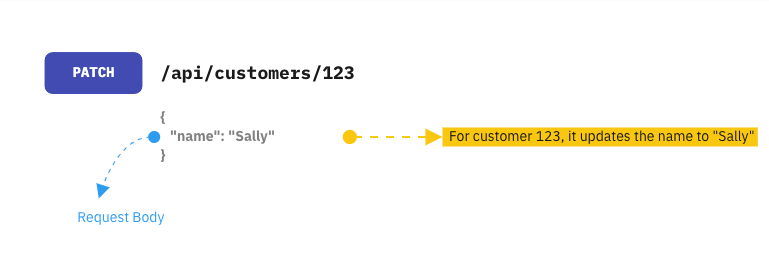
PATCH Method
How to test an API with a PATCH method?
- Send a PATCH request to the server; the server will return the 2xx HTTP status code, which means: the request is successfully received, understood, and accepted.
- Perform the GET request and verify that the content is updated correctly.
- If the request payload is incorrect or ill-formatted, the operation must fail.
DELETE Method
As the name suggests, the DELETE method deletes a resource. The DELETE method is idempotent; regardless of the number of calls, it returns the same result.
Most APIs always return the 200 status code even if we try to delete a deleted resource but in some APIs, If the target data no longer exists, the method call would return a 404 status code.
How to test a DELETE endpoint?
- Call the POST method to create a new resource. Never test DELETE with actual Data. For example, first, create a new customer and then try to delete the customer you just created.
- Call the GET method for the deleted customer, which should return 404, as the resource no longer exists.
Testfully’s Multi-step tests allow you to create resources on the fly and use them for testing DELETE endpoints.
HEAD Method
One of the advantages of the HEAD method is that we can test the server if it is available and accessible as long as the API supports it, and it is much faster than the GET method because it has no response body. The status code we expect to get from the API is 200. Before every other HTTP method, we can first test API with the HEAD method.
OPTIONS Method
We use This method to get information about the possible communication options (Permitted HTTP methods) for the given URL in the server or an asterisk to refer to the entire server. This method is safe and idempotent.
Various browsers widely use the OPTIONS method to check whether the CORS (Cross-Origin resource sharing) operation is restricted on the targeted API or not.

How to test an OPTIONS endpoint
- Make an OPTIONS request and check the header and the status code that returns.
- Test the case of failure with a resource that doesn’t support the OPTIONS method.
TRACE Method
The TRACE method is for diagnosis purposes. It creates a loop-back test with the same request body that the client sent to the server before, and the successful response code is 200 OK. The TRACE method is safe and idempotent.
The TRACE method could be dangerous because it could reveal credentials. A hacker could steal credentials, including internal authentication headers, using a client-side attack.
How to test an API with a TRACE method?
- Make a standard HTTP request like a GET request to /api/status
- Replace GET with the TRACE and send it again.
- Check what the server returns. If the response has the same information as the original request, the TRACE ability is enabled in the server and works correctly.
CONNECT Method
The CONNECT method is for making end-to-end connections between a client and a server. It makes a two-way connection like a tunnel between them. For example, we can use this method to safely transfer a large file between the client and the server.
## Comparison of HTTP methods
Browser Support
Old browsers only supported the GET and POST HTTP methods. Nowadays, most modern browsers like IE, Firefox, Safari, Chrome, Opera support all standard HTTP methods.
FAQ
The PUT method modifies an existing resource, but the POST HTTP method creates a new resource. Therefore, the PUT method is safe and idempotent, while the POST method is neither safe nor idempotent.
What is the difference between PUT and PATCH?
The PUT method updates the resource by replacing the whole data, while the PATCH method partially updates the resource. Thus, The PUT method is safe and idempotent, but the PATCH method is neither safe nor idempotent.
Does the GET method accept the request body?
Requests using the GET methods should only be for fetching data, not carrying it, so it is better to avoid sending data loads to the server as it causes an error if the server doesn’t accept it. However, the specifications don’t prohibit it.
What does idempotency mean?
It means regardless of how many times a method runs, the result of a successfully performed request would be the same.
What is CORS?
CORS is a security checking mechanism that allows a web page or server from one domain or origin(domain, protocol, port) to access a resource with a different domain (a cross-domain request). There are two types of CORS requests, simple requests, and Preflighted requests.
